Machine Learning is a powerful branch of Computer Science that enables computers to learn from data and improve their predictions or decision-making without explicit programming. In other words, ML algorithms recognize patterns in vast datasets, allowing businesses to make smarter decisions and automate repetitive tasks. In this Machine Learning Tutorial, we will explore essential topics in Machine Learning, such as Feature Engineering, Supervised Learning, Ensemble Learning, Dimensionality Reduction, and a glimpse into Natural Language Processing (NLP). Along the way, we will also provide small code snippets for each concept to give you a hands-on introduction without going too in-depth.
Feature engineering is the process of transforming raw data into meaningful representations that machine learning models can interpret more effectively. This step plays a crucial role in building robust models.
Next, Feature selection is the process of identifying and selecting the most significant features in your dataset. This step helps reduce overfitting, increase model interpretability, and improve computational efficiency.
By selecting only the relevant features, we can help the model to avoid getting distracted by irrelevant information, which can degrade its performance.
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.datasets import load_iris
# Load the dataset
X, y = load_iris(return_X_y=True)
# Select the top 2 features
selector = SelectKBest(f_classif, k=2)
X_selected = selector.fit_transform(X, y)
print(X_selected[:5]) # Display the selected features
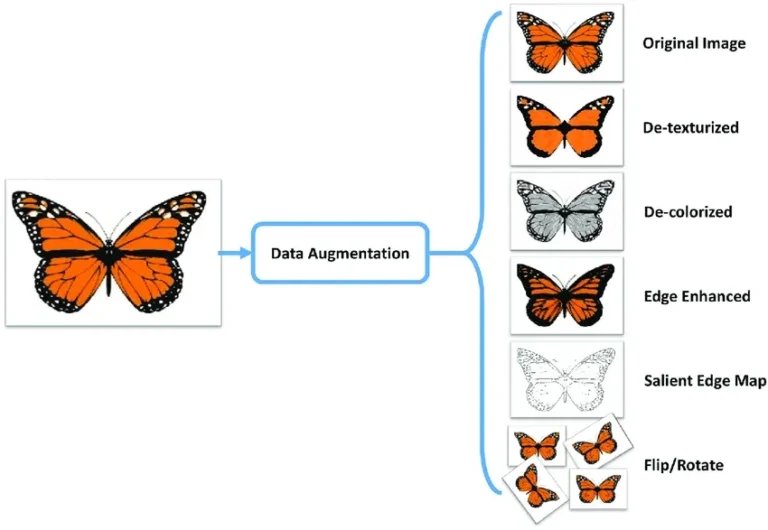
Augmenting the dataset allows the model to generalize better by learning from a more diverse range of examples.
from keras.preprocessing.image import ImageDataGenerator
# Define augmentation transformations
data_gen = ImageDataGenerator(rotation_range=30, width_shift_range=0.2, height_shift_range=0.2, zoom_range=0.2)
# Apply transformations to the image dataset
data_gen.fit(X_train) # Assuming X_train is the image dataset
Visualizing your data can offer deep insights into its structure and distribution. Tools such as Matplotlib, Seaborn, and Pandas make it easier to explore the structure and distribution of your dat in an intuitive way.
Visualization helps you uncover trends and patterns that may not be immediately apparent through numerical summaries. This leads to smarter feature selection and better modeling decisions.
Supervised learning involves training an algorithm on a labeled dataset. This means that for every input, there is a corresponding output, and the algorithm learns to map the input to the output. Supervised learning can be categorized into Regression and Classification tasks.
Regression is used to predict continuous values. For instance, predicting a house’s price based on features like size, number of rooms, and location.
from sklearn.linear_model import LinearRegression
# Simple training dataset
X = [[1], [2], [3], [4]]
y = [10, 20, 30, 40]
# Train the model
model = LinearRegression().fit(X, y)
# Predict for a new value
print(model.predict([[5]])) # Predict the output for input 5
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# Load dataset
iris = load_iris()
X, y = iris.data, iris.target
# Train the Logistic Regression model
model = LogisticRegression(max_iter=200)
model.fit(X, y)
# Predict a class label for a new sample
print(model.predict([[5.1, 3.5, 1.4, 0.2]])) # Classify a sample
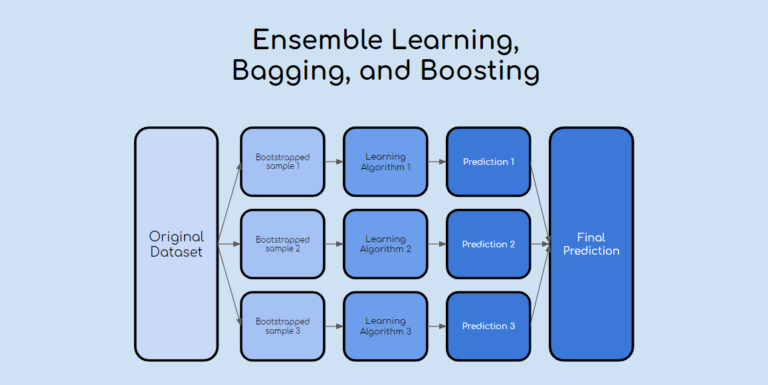
Ensemble learning enhances model performance by combining the predictive strengths of multiple models to improve overall performance. These techniques are especially useful for often reducing model variance and improve generalization.
Random Forest is one of the most popular ensemble methods. It builds several decision trees and merges their predictions, either by averaging or majority voting, to arrive at the final result.
By combining multiple trees, Random Forest reduces the likelihood of overfitting, which is common with individual decision trees. As a result, it delivers more reliable predictions on both training and datasets.
from sklearn.ensemble import RandomForestClassifier
# Load dataset
X, y = load_iris(return_X_y=True)
# Train Random Forest model
model = RandomForestClassifier(n_estimators=100)
model.fit(X, y)
# Predict a class label for a new sample
print(model.predict([[5.1, 3.5, 1.4, 0.2]]))
Unsupervised learning focuses on uncovering hidden pattern in data without the need for labeled inputs. In this approach, algorithm tries to find hidden patterns in the data without being given explicit labels. The main types of unsupervised learning are clustering and dimensionality reduction.
from sklearn.neighbors import KNeighborsClassifier
# Load dataset
X, y = load_iris(return_X_y=True)
# Train KNN model
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X, y)
# Predict a class label for a new sample
print(model.predict([[5.1, 3.5, 1.4, 0.2]])) # Classify new sample
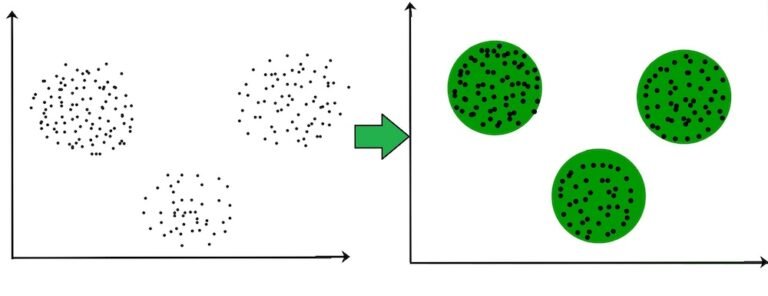
K-Means is an unsupervised learning algorithm that groups data points into clusters based on their similarities. As a result, it helps uncover pattern in data may not be immediately apart, making it powerful tool for data exploration and and analysis.
On the other end, Dimensionality reduction refers to techniques that reduce the number of input variables or features in a dataset, while retaining the most important information., as it is essential for dealing with high-dimensional datasets.
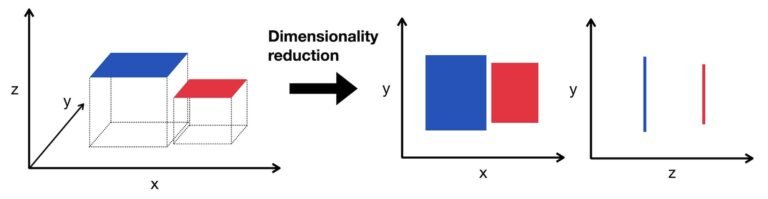
PCA is a widely used technique for reducing the dimensionality of datasets. Specifically, it works by projecting data onto new, smaller dimensions that capture the most variance. In other words, it transforms the original features into set of linearly uncorrelated components.
Consequently, PCA helps in speeding up the learning process and improving model performance. Moreover, it reduces risk of overfitting by removing irrelevant features. As a result, models become more efficient, easier to interpret and often yield better generalization.
from sklearn.decomposition import PCA
# Load dataset
X, _ = load_iris(return_X_y=True)
# Apply PCA to reduce dimensionality
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
print(X_reduced[:5]) # Display the reduced dataset
A correlation matrix helps identify relationships between features in a dataset. Specifically, it is often used for identifying multicollinearity or redundant features. Therefore, analyzing this matrix can guide better feature selection decisions.
Natural Language Processing focuses on the interaction between computers and humans using natural language. In the context of machine learning, it involves converting text into numerical data that machines can interpret.
These techniques are used to convert textual data into vectors, thus enabling machines to analyze and learn from it effectively.
Additionally, Tokenization is the process of breaking down text into individual words or sentences. As a result, it simplifies the structure of the data, making it easier for algorithms to process and learn patterns.
from nltk.tokenize import word_tokenize
# Example sentence
sentence = "Machine learning is a fascinating field."
# Tokenize the sentence into words
tokens = word_tokenize(sentence)
print(tokens) # ['Machine', 'learning', 'is', 'a', 'fascinating', 'field', '.']